2021 資訊之芽
第一次大作業
by Jason & Harry 🌱第一次大作業主題揭曉
🎉 Web Crawler with C(++) 🎉
什麼是爬蟲?
🐍
什麼是爬蟲?
網路爬蟲(英語:web crawler),也叫網路蜘蛛(spider),是一種用來自動瀏覽全球資訊網的網路機器人。其目的一般為編纂網路索引。
簡單來說
爬蟲就是一個自動化從網頁搜集資料的程式!
一支合格的爬蟲需要 ...
連上網路 ➔ 在網頁間移動 ➔ 擷取資料
一支合格的爬蟲需要連上網路
所以寫這次的大作業需要網路
如果家裡沒有要請爸爸媽媽去辦ㄛ!
一支合格的爬蟲需要連上網路
要怎麼讓 C(++) 程式連上網路呢?
用別人寫好的 Library!
要怎麼讓 C(++) 程式連上網路呢?

How does libcurl work?

我們已經幫各位把要用的功能包好 function 了
不過有興趣的可以自己去 liburl 網站研究研究 🧐
取得網頁內容
// Request a page by url, the response content is stored
// in global char array buffer[], while status code (eg.
// 200, 404) is returned.
int requestPage(char url[]);
這個函數是各位在寫大作業一時最基本的工具喔!
Example Usage
char url[MAX_LEN] = "https://curl.se/libcurl/";
int status;
do {
status = requestPage(url);
} while (status != 200);
cout << buffer << endl;
現在我們的程式可以連上網路了!

一支合格的爬蟲需要在網頁間移動
Scenario 1 - Paging
假設第 2 頁的網址長這樣:
https://books.toscrape.com/catalogue/page-2.html
一支合格的爬蟲需要在網頁間移動
Scenario 1 - Paging
那麼第 n 頁的網址應該長這樣:
https://books.toscrape.com/catalogue/page-n.html
一支合格的爬蟲需要在網頁間移動
要怎麼自動爬完所有頁數呢?
int page, status;
char url[MAX_LEN];
char tem[] = "https://books.toscrape.com/catalogue/page-%d";
for(page = 0; status != 404; page++){
sprintf(url, tem, page);
status = requestPage(url);
// some other logic to do with buffer[]
}
一支合格的爬蟲需要在網頁間移動
其他 Scenario?
就交給你各位去想啦 😉
一支合格的爬蟲需要擷取資料
要怎麼從茫茫 html 大海中撈出我們要的資料呢?
一支合格的爬蟲需要擷取資料
Q1. 怎麼描述想要的資料在哪裡?

一支合格的爬蟲需要擷取資料
DOM Tree Example
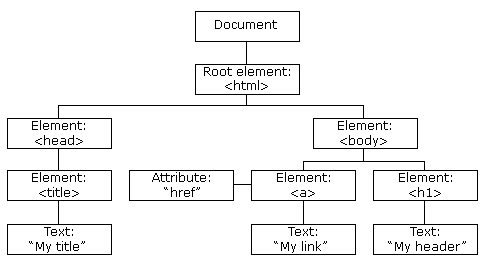
html > body > h1
一支合格的爬蟲需要擷取資料
Demo Time
一支合格的爬蟲需要擷取資料
我們可以用 Google 出的 Gumbo Parser 來把 html 轉換成 DOM tree

一支合格的爬蟲需要擷取資料
同樣的我們也幫各位把這功能包好 function 了
// Parse html in to global CDocument Object doc,
// remember to parse html before stripping contents!
void parseHtml(const char html[]);
// Strip content within global doc with specified CSS
// selector, the stripped content is stored in global
// char array stripped[], if there is no matching nodes
// then it returns values other than 0
int stripContent(const char selector[]);